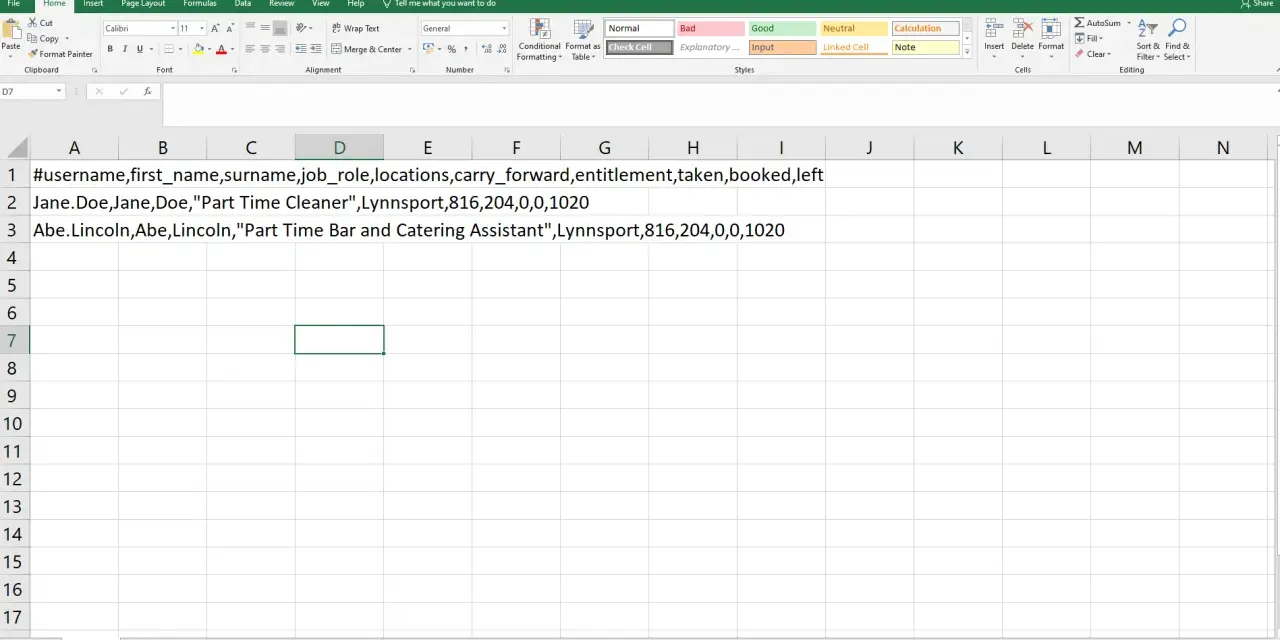
CSV to jeden z najprostszych sposobów zapisu tabeli w postaci tekstu, dlatego świetnie sprawdza się przy eksporcie danych z systemów, arkuszy i baz. W praktyce najwięcej problemów nie wynika z samego formatu, tylko z separatorów, kodowania znaków i tego, co zrobić z danymi po stronie PDF. W tym tekście pokazuję, kiedy ten format naprawdę ma sens, jak go bezpiecznie otwierać i zapisywać oraz gdzie kończą się jego możliwości.
Najważniejsze rzeczy o CSV w kilku punktach
- To tekstowy zapis tabeli, a nie pełny arkusz z formatowaniem.
- Najlepiej sprawdza się przy imporcie, eksporcie i automatyzacji.
- W polskich ustawieniach często spotkasz średnik zamiast przecinka jako separator.
- Problemy zwykle powodują kodowanie, cudzysłowy, daty i liczby zapisane po swojemu.
- PDF nadaje się do prezentacji i archiwum wyglądu, CSV do pracy na danych.
Czym jest CSV i dlaczego tak często wraca w pracy z danymi
Najprościej mówiąc, CSV to tabela zapisana jako zwykły tekst. Każdy wiersz odpowiada jednemu rekordowi, a kolumny są oddzielone separatorem, najczęściej przecinkiem albo średnikiem. To właśnie ta prostota sprawia, że format jest tak popularny w eksportach z CRM-ów, sklepów internetowych, programów księgowych i baz danych.
Ja traktuję CSV przede wszystkim jako format wymiany, a nie format „ładnego wyglądu”. Nie przechowuje kolorów komórek, scalonych pól, wykresów ani wielu arkuszy. Zyskujesz za to coś ważniejszego: łatwość przenoszenia danych między różnymi programami i systemami, nawet jeśli nie są ze sobą kompatybilne.
To dlatego CSV tak dobrze sprawdza się przy listach kontaktów, zamówieniach, stanach magazynowych, raportach sprzedaży czy prostych zestawieniach finansowych. Jeśli dane mają być później filtrowane, sortowane, importowane do innego narzędzia albo obrabiane automatycznie, ten format zwykle wygrywa z bardziej „efektownymi” alternatywami. Teraz warto zobaczyć, jak jest zbudowany od środka, bo tam kryje się większość praktycznych pułapek.
Jak wygląda struktura takiego pliku w praktyce
W dobrze zrobionym CSV na pierwszy rzut oka wszystko jest banalne: pierwszy wiersz często zawiera nagłówki kolumn, a kolejne wiersze dane. Problem zaczyna się wtedy, gdy w treści pojawiają się przecinki, średniki, znaki nowej linii albo polskie znaki, a program otwierający próbuje „zgadnąć” układ tabeli po swojemu.
Warto zapamiętać kilka zasad, które w praktyce decydują o tym, czy import się uda:
| Element | Co oznacza | Na co uważać |
|---|---|---|
| Wiersz | Jedna obserwacja, rekord albo pozycja | Każdy wiersz powinien mieć spójną liczbę kolumn |
| Separator | Znak oddzielający kolumny | W Polsce często działa średnik, bo przecinek bywa używany w liczbach |
| Nagłówek | Opis nazw kolumn w pierwszym wierszu | Warto go mieć, bo ułatwia import i późniejszą analizę |
| Cudzysłowy | Zabezpieczają pola z separatorem, przecinkami lub nową linią | Jeśli pole zawiera cudzysłów, zwykle zapisuje się go podwójnie |
| Kodowanie | Sposób zapisu znaków, np. UTF-8 | Źle dobrane kodowanie psuje polskie znaki i znaki specjalne |
Najważniejszy wniosek jest prosty: CSV nie jest „samowystarczalny” w taki sposób, jak wielu użytkowników oczekuje. To format, który działa dobrze tylko wtedy, gdy nadawca i odbiorca mają zgodne założenia co do separatora, kodowania i sposobu zapisu danych. Z tego przechodzę płynnie do najczęstszej operacji, czyli otwierania i zapisywania w Excelu.
Jak otworzyć i zapisać dane w Excelu bez rozjechanych kolumn
W praktyce najbezpieczniej jest importować dane, a nie tylko otwierać je podwójnym kliknięciem. Excel potrafi sam źle rozpoznać separator, zamienić kody na daty albo źle odczytać polskie znaki, jeśli plik został zapisany w innym kodowaniu niż oczekuje program.
Jeśli pracujesz w Excelu, zacząłbym od importu z zakładki danych i ręcznego wskazania separatora. To daje większą kontrolę niż automatyczne otwarcie pliku. W skrócie wygląda to tak:
- Otwórz pusty arkusz lub nowy skoroszyt.
- Wejdź w import z danych tekstowych lub z CSV.
- Wybierz właściwy separator, zwykle przecinek albo średnik.
- Sprawdź podgląd kolumn przed zatwierdzeniem.
- Jeśli widzisz błędy w polskich znakach, zmień kodowanie na UTF-8 i zaimportuj ponownie.
Nie każdy plik wymaga tego samego podejścia. Prosty eksport z jedną tabelą i bez znaków specjalnych często otworzy się bez problemu. Jeśli jednak dane pochodzą z systemu sprzedażowego, zawierają kwoty, numery katalogowe, kody pocztowe albo dłuższe opisy, lepiej nie liczyć na domyślne ustawienia programu. To właśnie w takich plikach najłatwiej o błędy, które później kosztują najwięcej czasu.
Najczęstsze błędy, które psują import
Tu zwykle widzę te same problemy, niezależnie od branży. Sam format jest prosty, ale dane biznesowe rzadko są idealnie czyste. W efekcie jeden źle zapisany znak potrafi przesunąć całą kolumnę i zniekształcić cały raport.
- Niezgodny separator - plik zapisany z przecinkami trafia do programu, który oczekuje średników.
- Przecinek dziesiętny - liczby typu 12,50 mogą zostać błędnie potraktowane jako dwie wartości.
- Wiodące zera - kody pocztowe, numery części i identyfikatory mogą stracić zera na początku.
- Daty interpretowane automatycznie - zapis 03-04 bywa zamieniany na datę według lokalnych reguł programu.
- Cudzysłowy w treści - jeśli nie są poprawnie zapisane, rozbijają strukturę wiersza.
- Znaki nowej linii w komórce - długi opis może rozciąć rekord na kilka wierszy i zepsuć import.
Najlepsza praktyka, jaką polecam, jest prosta: po eksporcie zawsze sprawdź pierwsze kilka wierszy w czystym arkuszu lub w edytorze tekstu. Jeśli coś wygląda podejrzanie już na początku, cały plik prawdopodobnie wymaga poprawy. A skoro dane często żyją nie tylko w arkuszu, ale też w dokumentach, naturalnie dochodzimy do porównania z PDF.
CSV a PDF kiedy wybrać który format
To porównanie naprawdę pomaga podejmować decyzje. CSV i PDF rozwiązują dwa różne problemy, więc traktowanie ich jak zamienników prowadzi do frustracji. Jeden format służy do pracy na danych, drugi do zachowania wyglądu dokumentu.
| Kryterium | CSV | |
|---|---|---|
| Główny cel | Import, eksport i analiza danych | Prezentacja, udostępnianie i druk |
| Edycja | Łatwa w arkuszu lub edytorze tekstu | Trudniejsza, często wymaga specjalnego narzędzia |
| Wygląd | Brak formatowania | Zachowany układ, typografia i grafika |
| Automatyzacja | Bardzo dobra | Ograniczona, chyba że użyjesz ekstrakcji danych |
| Najlepsze zastosowanie | Integracje, raporty do systemów, analityka | Umowy, raporty finalne, materiały do czytania |
Jeśli wysyłasz dane do programu, bazy albo sklepu internetowego, zwykle lepszy będzie CSV. Jeśli chcesz, by odbiorca zobaczył dokładnie taki sam układ strony jak u Ciebie, lepiej sprawdzi się PDF. W mojej ocenie to najważniejsze rozróżnienie: CSV jest do obróbki, PDF do prezentacji. Gdy dokument jest już w PDF, pojawia się jednak kolejne pytanie: czy da się z niego odzyskać tabelę?
Jak wyciągnąć tabelę z PDF i zamienić ją na CSV
Da się, ale nie zawsze bez strat. Najlepszy scenariusz to taki, w którym PDF jest wygenerowany cyfrowo i zawiera prawdziwy tekst, a nie tylko obraz skanu. Wtedy eksport do arkusza lub użycie narzędzia do rozpoznawania struktury tabel zwykle daje sensowny punkt wyjścia.
Jeśli PDF jest skanem, zaczyna się OCR, czyli rozpoznawanie tekstu ze zdjęcia dokumentu. To działa coraz lepiej, ale nadal wymaga kontroli. Kolumny potrafią się przesunąć, mylić się numery, a wielowierszowe opisy lub zagnieżdżone tabele często trzeba poprawić ręcznie. Dlatego nie obiecywałbym „jednego kliknięcia” w przypadku skomplikowanych zestawień.
Praktycznie najlepiej działa taki schemat:
- Sprawdź, czy PDF zawiera tekst, czy tylko obraz.
- Wykonaj eksport do arkusza lub tabeli, jeśli narzędzie to oferuje.
- Porównaj kilka pierwszych i kilka losowych wierszy z oryginałem.
- Popraw nagłówki, separator i typy danych.
- Zapisz wynik jako CSV dopiero wtedy, gdy struktura jest stabilna.
To ważne zwłaszcza przy fakturach, raportach finansowych, zestawieniach magazynowych i archiwach skanów. Im bardziej złożony układ PDF, tym większa szansa, że automatyczna konwersja będzie tylko przybliżeniem. I właśnie dlatego na końcu warto ustalić prosty standard pracy, zamiast za każdym razem improwizować.
Prosty standard eksportu oszczędza więcej czasu niż ręczne poprawki
Gdybym miał wybrać kilka nawyków, które naprawdę poprawiają jakość danych, wskazałbym te same cztery rzeczy: spójny separator, UTF-8, jednoznaczne nagłówki i brak formatowania zależnego od programu. To niewiele, ale w praktyce robi ogromną różnicę przy imporcie do innych systemów.
- Uzgodnij separator z odbiorcą, zamiast zakładać, że każdy program rozumie to samo.
- Używaj UTF-8, jeśli plik ma zawierać polskie znaki lub symbole specjalne.
- Nie scalaj komórek i nie ukrywaj danych w komentarzach lub kolorach.
- Trzymaj kody, identyfikatory i numery w formie tekstowej, jeśli nie chcesz ich przekształcenia.
- Przed wysłaniem otwórz plik i sprawdź, czy pierwsze wiersze wyglądają dokładnie tak, jak powinny.
Jeżeli pracujesz regularnie z raportami, integracjami albo eksportem z PDF do arkusza, taki prosty standard jest po prostu tańszy niż ręczne poprawianie błędów po każdej operacji. Dobrze przygotowany CSV nie zwraca na siebie uwagi, bo po prostu działa, a to w pracy z danymi jest najlepszy możliwy rezultat.